Hey everybody,
Today a customer approached me with the following question:
Would it be possible to get all files and folders from a Seafile Server and write the complete structure into a SeaTable base?
The answer is definitely yes, and I will show you how you can do this.
Step 1: set up a new base
First, you have to create a new base with the following structure. My table has the name Files in Repo.

Step 2: create a new python script
Copy-and-paste the following code and adapt it to your needs. I will explain later on how the script works.
import os
import sys
import requests
from seatable_api import Base, context
from datetime import datetime
server_url = context.server_url
api_token = context.api_token
table_name = 'Files in Repo'
seafile_url = 'https://your-seafile-server-url'
seafile_repo = 'add-the-repo-id-like: (43107b73-d90d-4552-937a-c1aa8baef43b)'
####################
# Option 1: Obtain Seafile Auth-token (username and password)
####################
#seafile_user = 'your-seafile-user'
#seafile_pw = 'your-seafile-password'
#url = seafile_url + "/api2/auth-token/"
#data = {'username': seafile_user, 'password': seafile_pw}
#token = requests.post(url, json=data).json()['token']
####################
# Option 2: use seafile api-token
####################
token = 'add-the-api-token-of-a-user-who-has-access-to-this-repo'
####################
# SeaTable Base-Auth
####################
base = Base(api_token, server_url)
base.auth()
####################
# get all files from this repo (including subfolders)
####################
def get_files(path):
url = seafile_url + '/api2/repos/' + seafile_repo + '/dir/?p=/' + path
headers = {
'Authorization': 'Token {}'.format(token),
'Accept': 'application/json; indent=4'
}
resp = requests.get(url,headers=headers)
for f in resp.json():
# for debugging:
# print(f)
if f['type'] == 'file':
size = str(round(f['size'] / 1000000,2)) + ' MB'
mtime = str(datetime.fromtimestamp(f['mtime']))
base.append_row(table_name, {'Size': size, 'Name': f['name'], 'Last Update': mtime, 'Path': path, 'Last Modifier': f['modifier_name']})
else:
get_files(path + '/' + f['name'])
# start with root-folder of the repo
get_files("")
print("Hasta la vista, baby. I'll be back...")
how this looks like
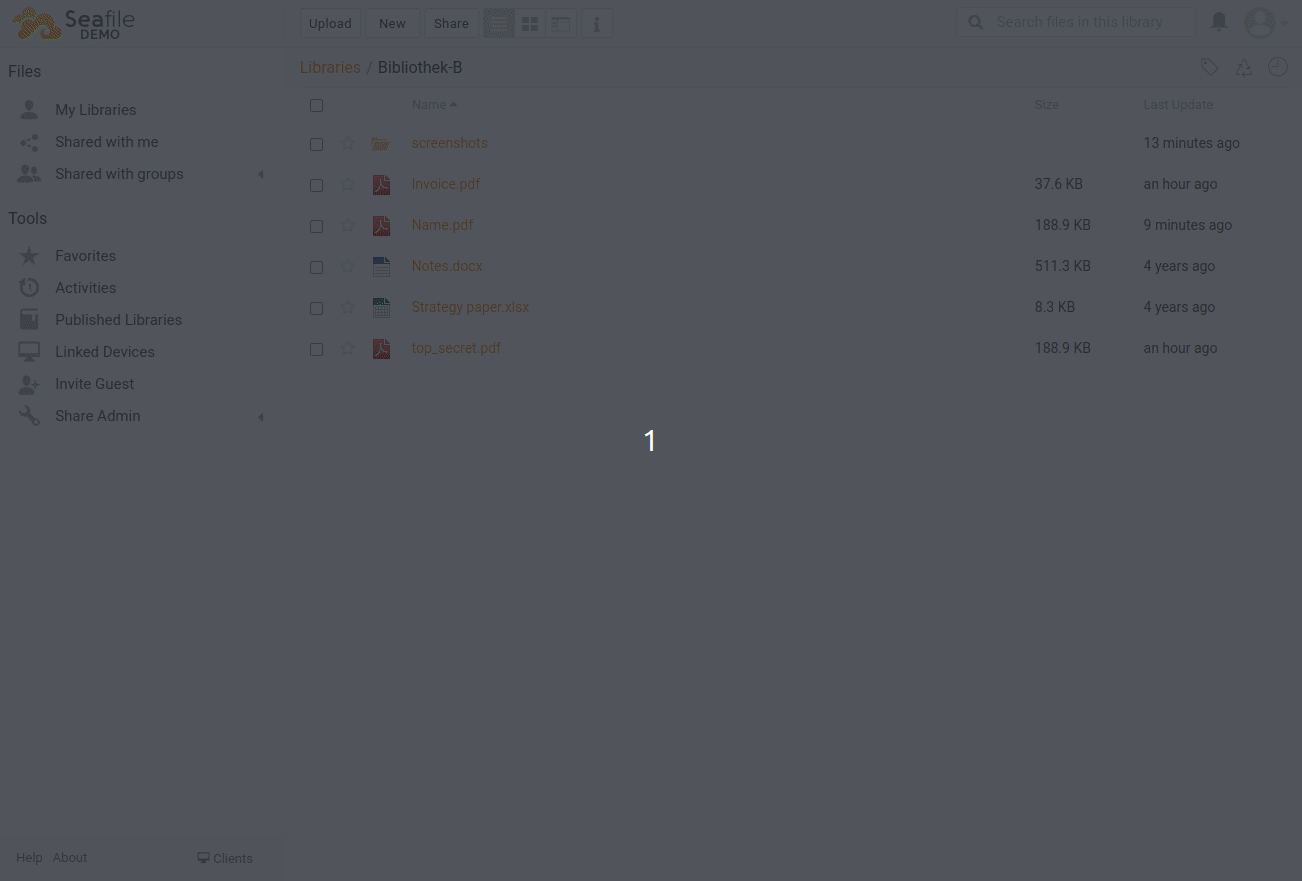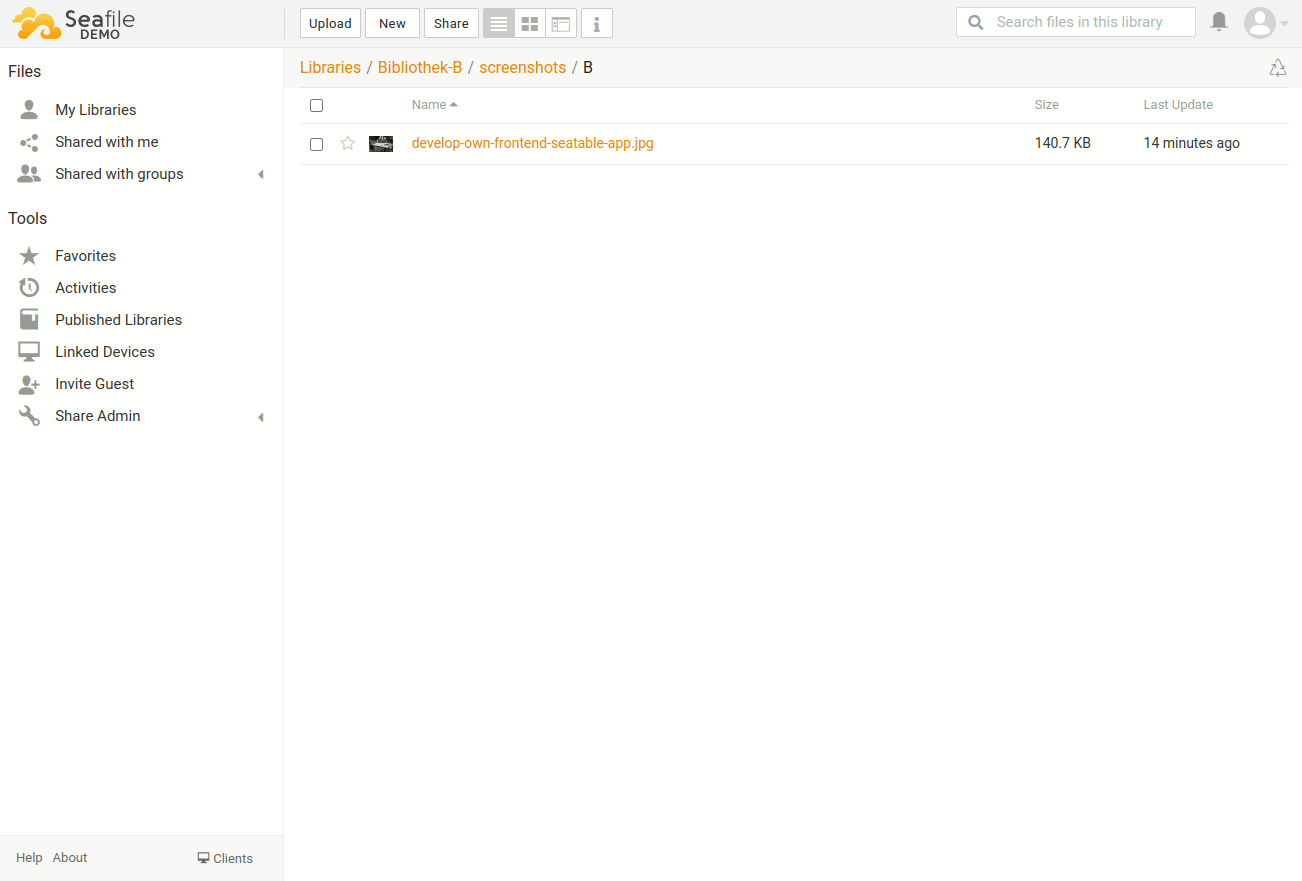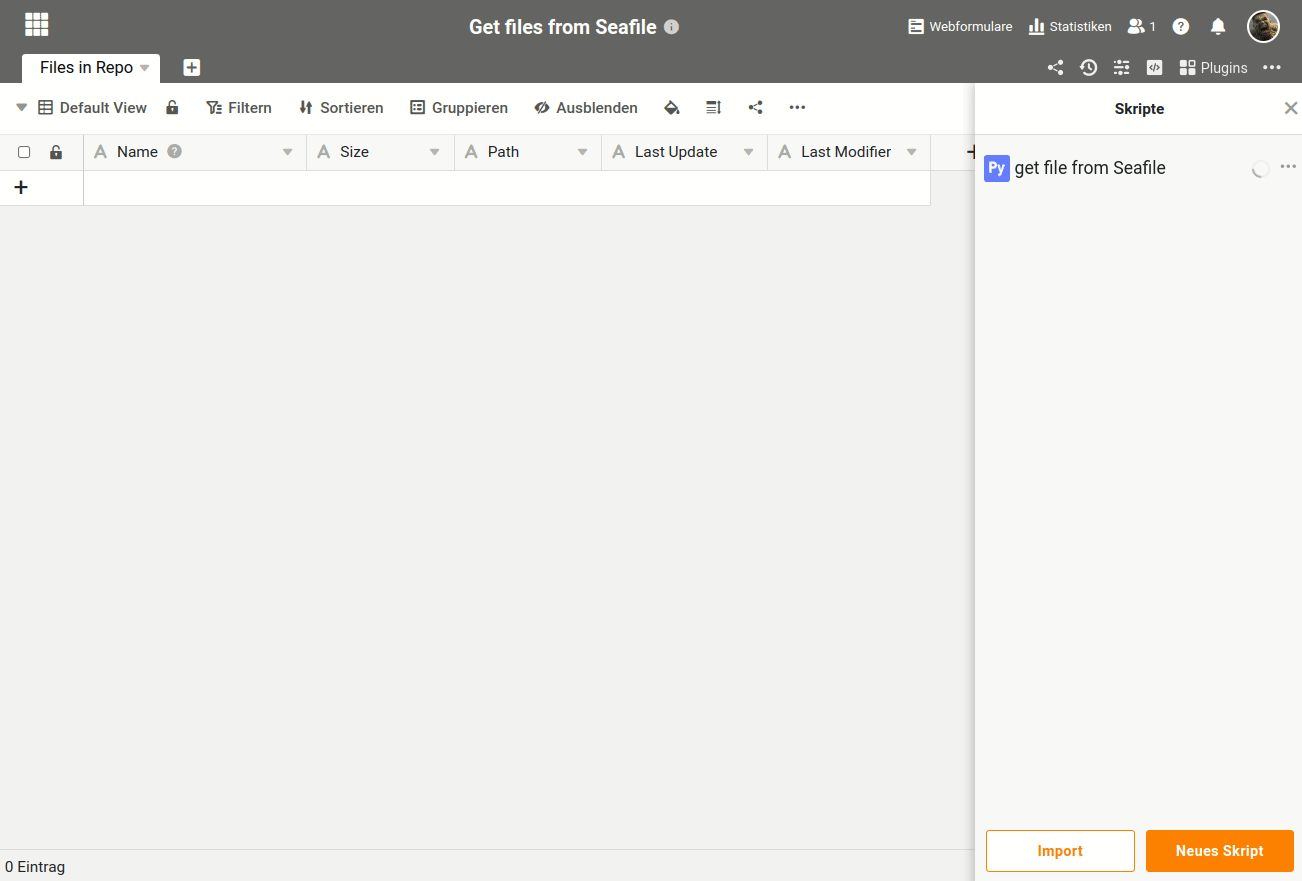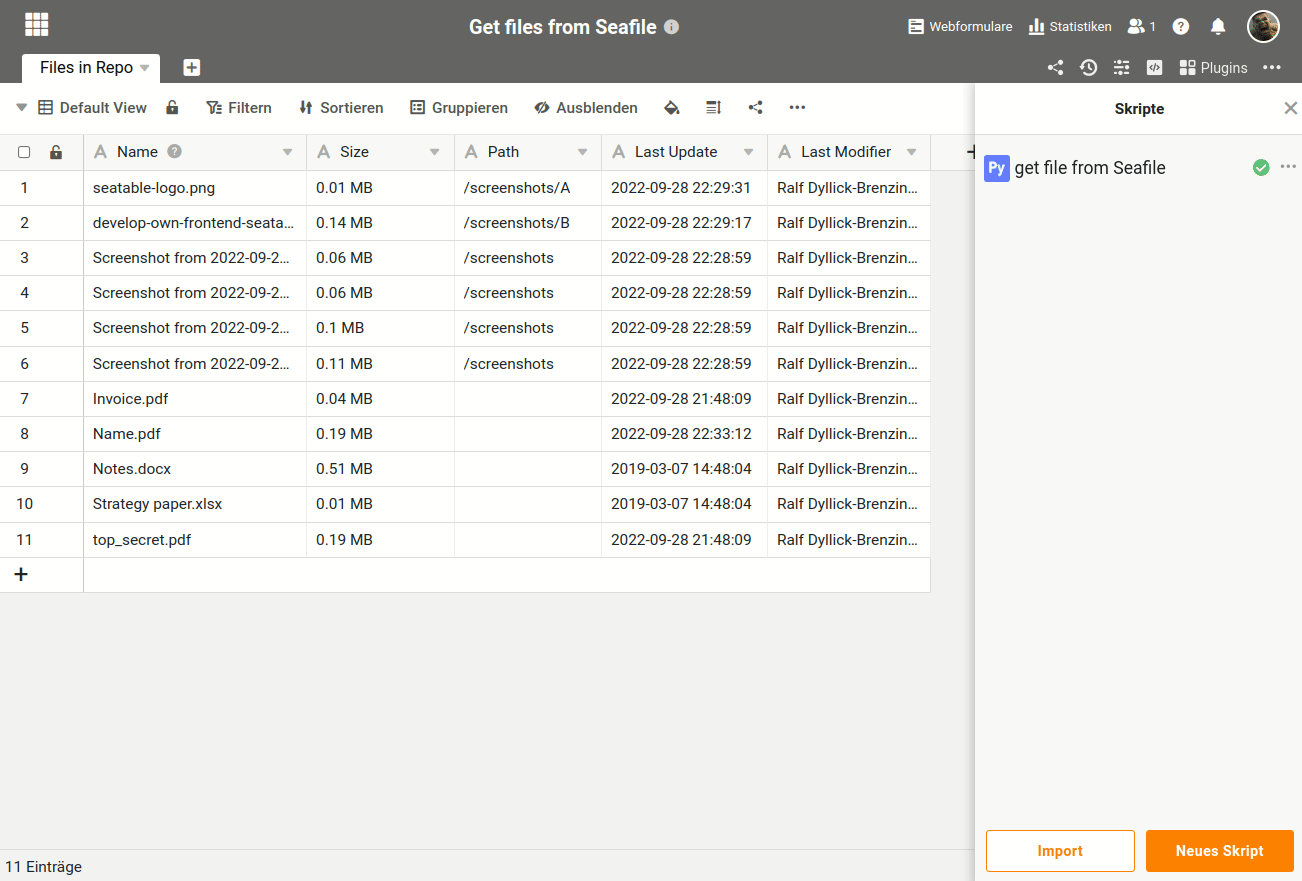
Here is a short video how the result will look like. The python-script will walk through the complete folder structure of one library in Seafile and write all the information to the SeaTable base. The size is rounded to MB and the modification timestamp is translated into a human-readable date.
Step by step python script explained
Part 0
import os
import sys
import requests
from seatable_api import Base, context
from datetime import datetime
server_url = context.server_url
api_token = context.api_token
table_name = 'Files in Repo'
seafile_url = 'https://your-seafile-server-url'
seafile_repo = 'add-the-repo-id-like: (43107b73-d90d-4552-937a-c1aa8baef43b)'
Well, what should I say. First I load all the required python modules and then I define some basic variables. You have to change the variables to match your setup.
Part 1
####################
# Option 1: Obtain Seafile Auth-token (username and password)
####################
#seafile_user = 'your-seafile-user'
#seafile_pw = 'your-seafile-password'
#url = seafile_url + "/api2/auth-token/"
#data = {'username': seafile_user, 'password': seafile_pw}
#token = requests.post(url, json=data).json()['token']
####################
# Option 2: use seafile api-token
####################
token = 'add-the-api-token-of-a-user-who-has-access-to-this-repo'
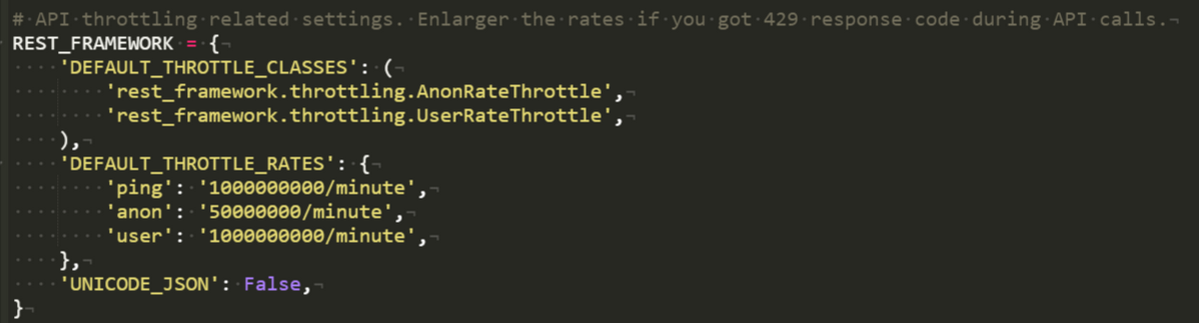
In the next section, I want to use the Seafile-API to get all files from a repo. Every API-call has to be authenticated with a token. This token can either be generated for a username + password combination (=Option 1) or you can add your token directly as a variable (=Option 2).
I would prefer Option 2 because you skip one API-call per script execution.
You can find more information about the authentication of API-calls at this page:
Part 2
base = Base(api_token, server_url)
base.auth()
This is necessary to append the file infos to the SeaTable base later on.
Part 3
def get_files(path):
url = seafile_url + '/api2/repos/' + seafile_repo + '/dir/?p=/' + path
headers = {
'Authorization': 'Token {}'.format(token),
'Accept': 'application/json; indent=4'
}
resp = requests.get(url,headers=headers)
for f in resp.json():
# for debugging:
# print(f)
if f['type'] == 'file':
size = str(round(f['size'] / 1000000,2)) + ' MB'
mtime = str(datetime.fromtimestamp(f['mtime']))
base.append_row(table_name, {'Size': size, 'Name': f['name'], 'Last Update': mtime, 'Path': path, 'Last Modifier': f['modifier_name']})
else:
get_files(path + '/' + f['name'])
# start with root-folder of the repo
get_files("")
Seafile has no API-call to get all files of library, including all subdirectories. Therefore, I define a function to get all files from one folder. Then I loop through the results. The result contains files and folder.
- if it is a file, I append the file info to the SeaTable base
- if it is a folder, I call the function again with a new path.
With this setup, it is possible to walk through the complete library with all subfolders.
If you have questions, please let me know.